The PIP Service is a standalone service of the Platform. You can use the PIP Service when you need data from external sources to support the Policy decision. The PIP Service guide is divided into the following sections:
- Management
- This section contains guides on how to manage and define Data Sources, Views, and PIP Caching.
- Operator
- Technical information about the PIP Operator Service configuration, variables, logging, and health.
PIP Overview
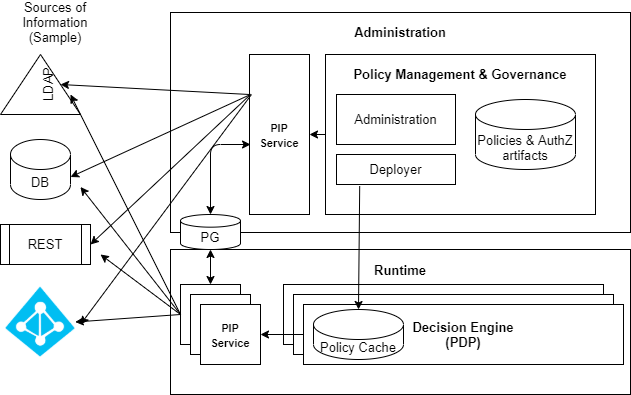
The PIP Service is based on the creation of:
• Data Sources: Foreign schemas connected to the external sources of information.
• Views: Virtual schemas that are based on the foreign schemas. A virtual schema can be based on a single foreign table or a combination of attributes from multiple foreign schemas and can also apply filters and other data manipulations.
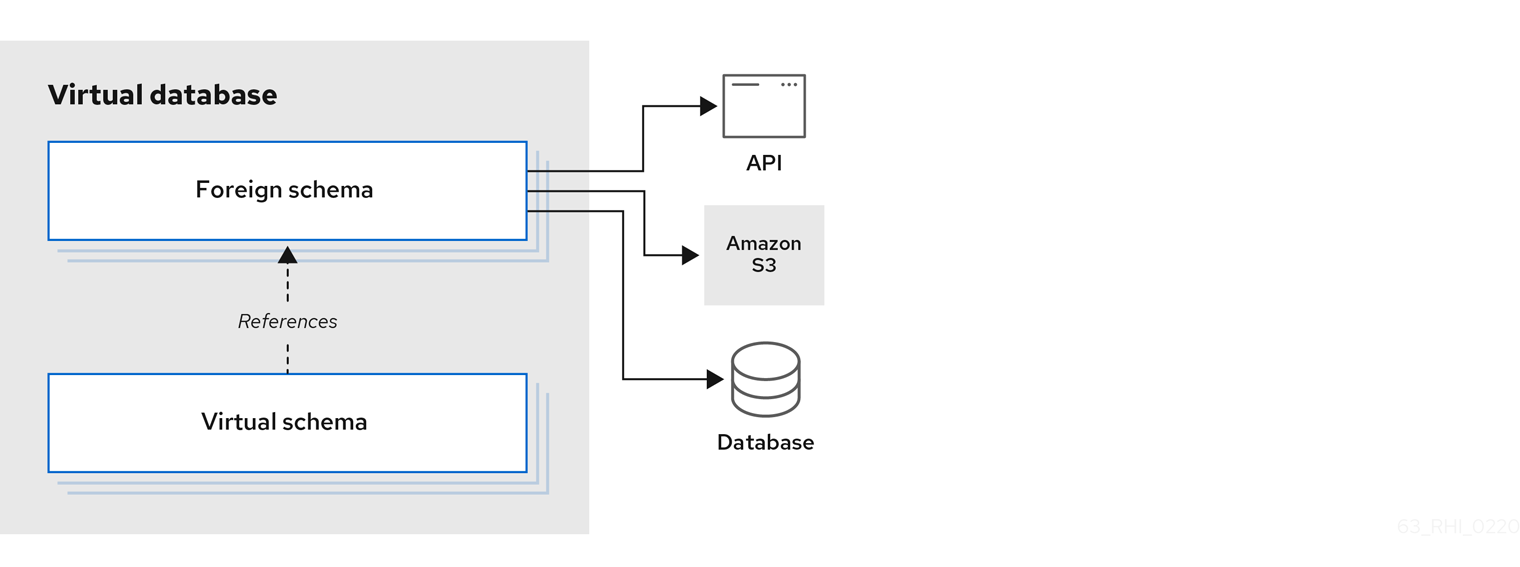
The virtual schema can be consumed by PDPs (Runtime service) such as an RDBMS source using JBDC connection. The result is a very powerful and flexible capability to combine Attributes from different Data Sources (even from multiple types), and use them to represent Identities or Assets for the Platform.
The PIP Service has its internal data model, which contains several objects that together represent the above-mentioned Data Sources and Views, including:
- Adapter – contains the Data Source type and some connection details. The Platform supports multiple adapters to connect with different types of sources (for example, Microsoft Active Directory, databases, etc.).
- Translator – paired with an adapter and acts as a logic layer determining aspects of data retrieval and import settings. The Translator has some configurable properties, but usually, the default values are sufficient.
- Source – responsible for the connection to a Data Source, using a specific adapter and Translator. It will be used to connect to a Data Source and pull data and metadata for foreign schemas.
- Model – a representation of the data structure of the foreign schema built based on the original source. It could be identical to the structure of the original Data Source, same attributes as the original source has, or a subset of the original Data Source.
- For example, if your Data Source is a DB table with many columns or an LDAP schema with a lot of properties, you can declare a model that will represent only part of the source columns/properties, and then when data is being fetched from the original Data Source, only these columns/properties will be selected into the foreign table.
- View – the declaration of the virtual schema containing the structure and data logic for fetching data from the foreign schema. As mentioned above the view will be used to create an external asset template or for mapping of an identity template, and data for the template will be consumed by PDP using JDBC connection as an RDBMS source. Internally the view is saved as another Model.
PIP Service Architecture
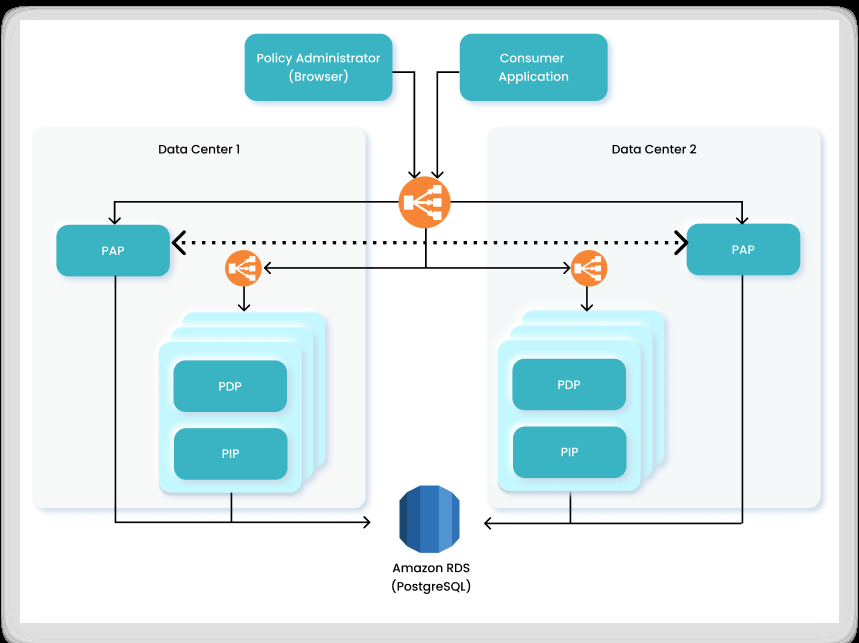
The PIP Service architecture can be designed in several ways. Following are two scenarios as examples of how the PIP Service can be integrated into an Organization.
Each involves two Data Centers, each with multiple PDP and PIP components and configured for high availability and redundancy. These Data Centers can be deployed in different regions, and each is configured with one or more Policy Administration Points (PAP) that are connected to a shared centralized database based on Amazon RDS (Relational Database Service).
Replication between the PAPs in the different Data Centers is performed by an internal functionality/module in the PAP (based on the OrientDB replication mechanism).
If any of the components go offline for any reason, even if an entire Data Center malfunctions, the load balancer automatically redirects queries to the other Data Center with no interruption or downtime.
Scenario 1: Single Entry Point
In this scenario, the organization’s applications communicate with a single main entry point. At this entry point, a load balancer is responsible for directing authorization queries to the relevant PDP in Data Center 1 or Data Center 2 for resolution.
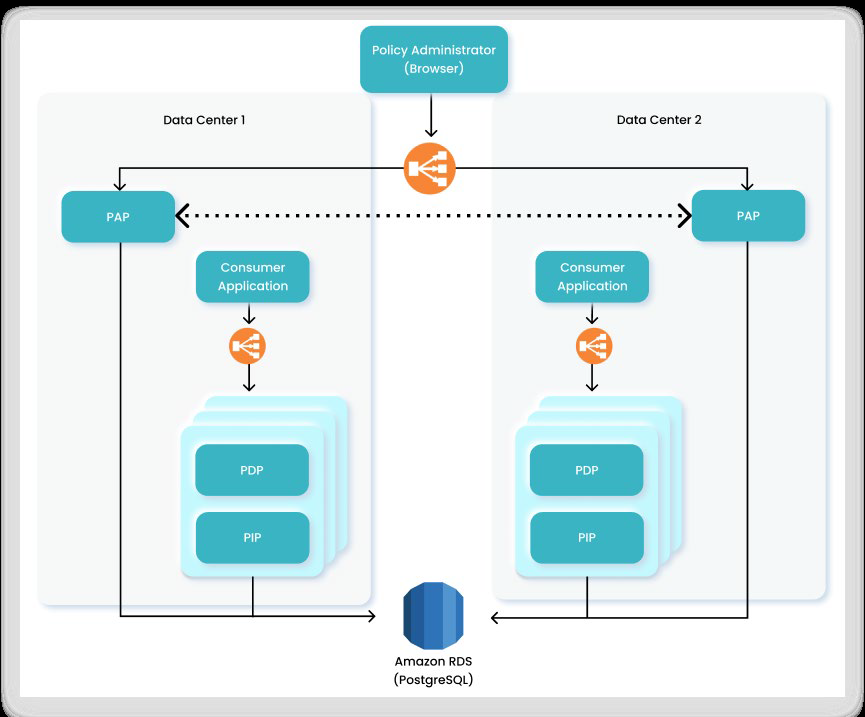
Scenario 2: Multiple Entry Points
In this scenario, the organization’s applications have an instance in each Data Center, and they communicate with a local entry point. At these entry points, a load balancer is responsible for directing authorization queries to the relevant PDP in the same Data Center.
The PIP (Policy Information Point) Service plays an important role in the Platform. It enables the policy decisions to feed from a large variety of external sources. The main advantages of the PIP service are:
- It supports a large variety of Data Sources
- It supports relationships between Attributes
- It simplifies management and configuration experience
- Automatic setup of templates
- That each PAA can be configured to run its own PIP service and can connect to different PIPs as needed.
Data Sources
The PIP Service supports many different adapter types for many types of external information sources including such common Data Sources as Oracle, MySQL, and many others. For each of the Policy Authorization Agents (PAA) that you have defined, you can configure one or more Data Sources.
For more information on Data Sources and on managing them, refer to our article on Data Sources.
Generating the DDL Statement
The DDL (Data Definition Language) field defines the structure of a table (columns and types) and determines what data will be fetched from the external Data Source. It uses a CREATE FOREIGN TABLE command, followed by a declaration of the Data Attributes and source-specific options.
For example, a Microsoft Active Directory model may define a foreign table LDAP_TEST with four Attributes, a BaseDN, and a flag to fetch the full directory tree:

Generate DDL from Import Properties
The Generate DDL function reads schema metadata from the Data Source and builds a DDL statement accordingly:
- If you provide both a table name and schema name in the import properties (e.g., for PostgreSQL), a DDL will be generated for that specific table.
- If you provide only a schema name, the generated DDL will include multiple foreign tables from that schema.
Note: Some import properties—such as
tableNamePatternandschemaPattern—support SQL-style wildcards:
_for a single character%for multiple characters
Connecting Multiple Models
You can connect multiple Models to the same Data Source, each with different names and settings. For example, one Oracle model can fetch all tables with a specific prefix, while another fetches a specific view.
- Translator Properties – key-value pairs that control how data is retrieved from the external source.
After configuring the Data Source and associated Models, click Sync Data Sources to retrieve schema metadata (not actual data) from all connected external sources.
For a list of supported Data Sources and how to manage them, click here.
Views
Virtual Views let you create customized, logical representations of your data without changing the underlying Data Sources. They behave like virtual tables, allowing you to combine, filter, and transform data from one or more sources to fit the templates needed for Policies. Views can be used as Assets or Identities information points and support advanced SQL-like operations such as JOIN, WHERE, CAST, and CONCAT.
For more details on creating and managing Views, see Managing Views.
Source and View APIs
APIs for managing sources and Views are available in the Developer Portal.
Refer to Source APIs and View APIs for more information.