The PIP Service is a standalone service of the Platform. You can use the PIP Service when you need data from external sources to support the Policy decision.
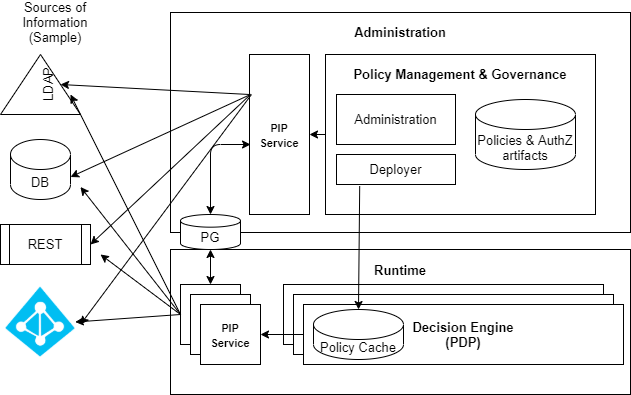
The PIP Service is based on the creation of:
• Data sources – Foreign schemas connected to the external sources of information.
• Views – Virtual schemas that are based on the foreign schemas. A virtual schema can be based on a single foreign table or a combination of attributes from multiple foreign schemas and can also apply filters and other data manipulations.
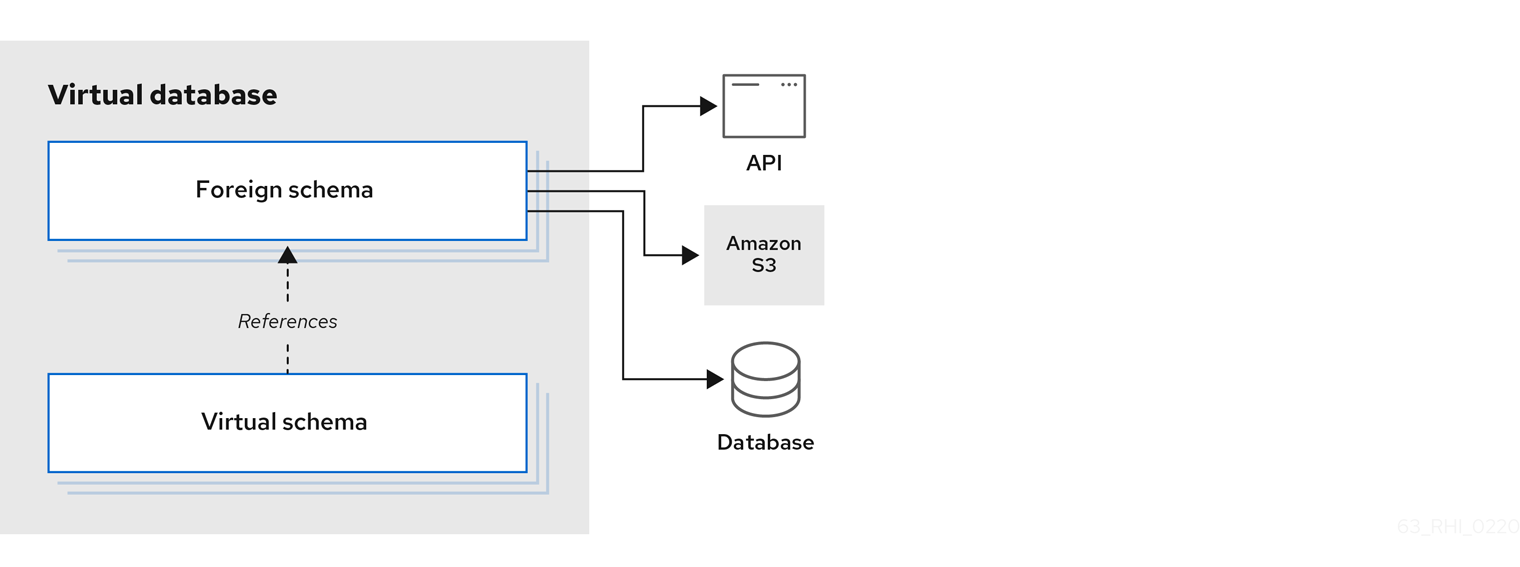
The Virtual schema then can be consumed by PDP (runtime service) such as an RDBMS source using JBDC connection. The result is a very powerful and flexible capability to combine Attributes from different Data Sources (even from multiple types), and use them to represent Identities or Assets for the Platform.
The PIP Service has its internal data model, which contains several objects that together represent the above-mentioned Data Sources and Views, including
- Adapter – contains the Data Source type and some connection details. The Platform supports multiple adapters to connect with different types of sources (for example, Microsoft Active Directory, databases, etc.).
- Translator – paired with an adapter and acts as a logic layer determining aspects of data retrieval and import settings. The Translator has some configurable properties, but usually the default values are sufficient.
- Source – responsible for the connection to a Data Source, using a specific adapter and Translator. It will be used to connect to a Data Source and pull data and metadata for foreign schemas.
- Model – a representation of the data structure of the foreign schema built based on the original source. It could be identical to the structure of the original Data Source, same attributes as the original source have, or a subset of the original Data Source.
- For example, if your Data Source is a DB table with many columns, or an LDAP schema with a lot of properties, you can declare a model that will represent only part of the source columns/properties and then when data is being fetched from the original Data Source, only these columns/properties will be selected into the foreign table.
- View – the declaration of the virtual schema containing the structure and data logic for fetching data from the foreign schema. As mentioned above the view will be used to create an external asset template or for mapping of an identity template, and data for the template will be consumed by PDP using JDBC connection as an RDBMS source. Internally the view is saved as another Model.
PIP Service Architecture
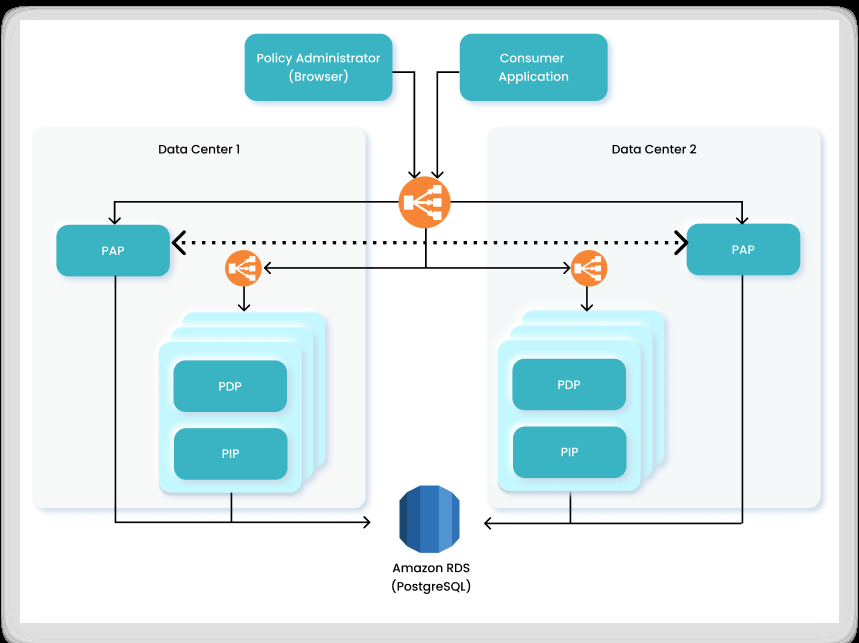
The PIP Service architecture can be designed in a number of ways. Following are two scenarios as examples of how the PIP Service can be integrated into an Organization.
Each involves two Data Centers, each with multiple PDP and PIP components and configured for high availability and redundancy. These Data Centers can be deployed in different regions, and each is configured with one or more Policy Administration Points (PAP) that are connected to a shared centralized database based on Amazon RDS (Relational Database Service).
Replication between the PAPs in the different Data Centers is performed by an internal functionality/module in the PAP (based on the OrientDB replication mechanism).
If any of the components go offline for any reason, even if an entire Data Center malfunctions, the load balancer automatically redirects queries to the other Data Center with no interruption or downtime.
Scenario 1: Single Entry Point
In this scenario, the organization’s applications communicate with a single main entry point. At this entry point, a load balancer is responsible for directing authorization queries to the relevant PDP in Data Center 1 or Data Center 2 for resolution.
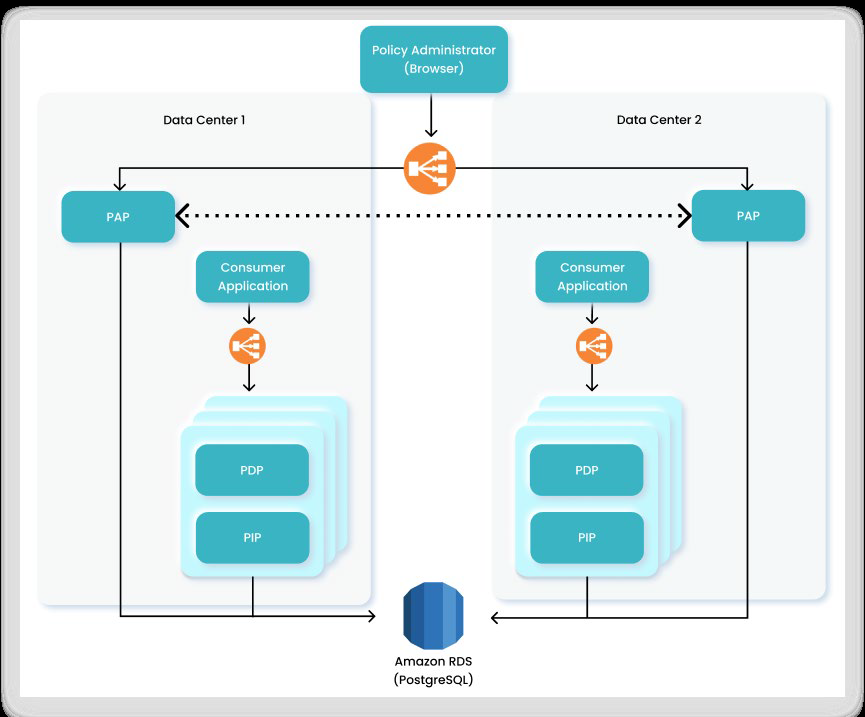
Scenario 2: Multiple Entry Points
In this scenario, the organization’s applications have an instance in each Data Center, and they communicate with a local entry point. At these entry points, a load balancer is responsible for directing authorization queries to the relevant PDP in the same Data Center.
Configuring PIP Settings
Information points are important in any policy management of an authorization solution. The objective of the Policy Information Points (PIPs) is to provide supporting data for the authorization decision. Dynamic authorization decisions rely on who the identity is, what the identity is trying to access, and the context of the access. All this information is often managed in different sources and is made available to the decision engine at the time of access.
The PIP (Policy Information Point) Service plays an important role in the Platform. It enables the policy decisions to feed from a large variety of external sources. The main advantages of the PIP service are:
- It supports a large variety of Data Sources
- It supports relationships between attributes
- It simplifies management and configuration experience
- Automatic set up of templates
- That each PAA can be configured to run its own PIP service and can connect to different PIPs as needed.
Data Sources
The PIP Service supports many different adapter types for many types of external information sources including such common Data Sources as Oracle, MySQL, and many others. For each of the Policy Authorization Agents (PAA) that you have defined, you can configure one or more Data Sources.
To access the Data Source List:
Each Data Source has its own unique configuration settings and requirements. Following is the general flow for most Adapters. For specific information on how to configure a Connection Adapter, contact Technical Support or (if currently available, refer to the appropriate content in the Online Documentation. Links to available sections follow the basic procedure detailed below).
Data Source Connection Adapters are divided into the following groups to help you find the Adapter you need more easily. The Connection Adapter groups include:
- Database (JDBC, MySQL, PostgreSQL, Oracle, Sybase, SQLServer, DB2, MongoDB, etc.)
- Web Application (Salesforce)
- Webservices (OData, REST, SCIM, etc.)
- User Repositories (LDAP, Azure AD)
To create a new Data Source:
-
Open the Tenant or Environment Settings screen and select PIP Settings.
-
Select an existing PAA from the list of available PAAs. The Data Source List and Views List for that PAA is displayed.
-
Click New Data Source.
-
Enter the Display Name for the new Data Source in the Data Source Details section.
-
In the Connection Adapter field, select the appropriate Connection Adapter. The Connection Adapters are organized in groups, as detailed above (and in alphabetical order within each group).
-
In the Connection Settings section, configure the connection to the external information source. Available fields depend on the selected Connection Adapter.
- Each adapter includes optional username and password fields. You can define connection credentials in one of three ways:
- Enter the username and password as clear text (not recommended outside sandbox environments).
- Use environment variables by enclosing them in brackets for better security and flexibility (e.g.,
[DOE-USER] [DOE-PASSWORD]). - If integrating with PlainID’s Secret Manager, reference credentials using
{{secret name}}.- For Secret Manager integration, use the syntax specific to your secret store. See Secret Management Configuration for details.
- Example:
{{store=HASHICORP_VAULT, key=my-database-credentials}}
- Example:
- For AWS RDS DB with AWS IAM Auth:
{{store=AWS_RDS_IAM_AUTH_STORE,key=test_user@shared-partner-mgmt-dev.cluster-g6wgs3hs1zff.eu-east-2.rds.amazonaws.com:5432/eu-east-2}}.
- For Secret Manager integration, use the syntax specific to your secret store. See Secret Management Configuration for details.
- Each adapter includes optional username and password fields. You can define connection credentials in one of three ways:
-
In the Models section, set a model name and complete other parameters for fetching relevant data objects from the external information source. Models offer a representation of the data structure of the foreign schema built based on the original source. It could be identical to the structure of the original Data Source, same attributes as the original source have, or a subset of the original Data Source. The Model name must be unique to the model and cannot contain special characters. The model size supports up to 4MB of DDL content to provide users with the ability to define intricate data structures in models or when generating a DDL for large database schemas.
-
In the Data Model Properties fields, there are possible key value pairs of configurations that determine the way metadata is fetched from the Data source. In some Data Source types, such as JDBC, it will determine how the DDL statement (see below) will be generated and which data objects from the external information source will be fetched into the model. An example for setting a property that will set only TABLES (and not VIEWS) from an RDBMS external information source:

Note: This functionality is not supported for all Adaptors. After all settings are defined, save the new Data Source with the connected Models, and click Sync Data Sources. This will sync all Data Sources and all models by fetching the data structure from the external information sources (it does not fetch any data from the external sources at this point).
Generating the DDL Statement
DDL, or Data Definition Language, is used to describe the Data Source table structure (columns and types of columns). The DDL field on the Data Source screen provides another option to set what data will be fetched from the external Data Source. It allows the user to write a DDL statement with a CREATE FOREIGN TABLE command followed by declaration of the Data Attributes for that model and specific options according to the source type.
An example for such DDL (for a Microsoft Active Directory model) might declare a foreign table LDAP_TEST with four data Attributes from the Active Directory, and add to it options part with BaseDN for the data fetching and an option to fetch data from all the tree:

Generate a DDL statement according to the Data Source details and import properties
The Generate DDL functionality reads schema metadata from the Data Source and creates DDL statements based on the imported schema structure.
As an example, setting a Postgres Data Source and adding import properties of table name and schema name, will generate a DDL.
Another example would be to set import properties only with schema name and the generated DDL will include creation of multiple foreign tables found in that schema.
You can add multiple Models for the same Data Source, each will have its unique name and will use different settings. By that you can, as an example, set an Oracle Data Source and connect to it one model that will fetch tables with a specific prefix in its name, and another model that will fetch a specific view from the oracle schema.
- Translator Properties – a list of possible key value pairs of configurations that can determine how and what data objects from the external information source will be fetched.
After all settings are defined, save the new Data Source with the connected Models, and click Sync Data Sources. This will sync all Data Sources and all models by fetching the data structure from the external information sources (it does not fetch any data from the external sources at this point).
For information on Supported Data Sources, click here.
Source and View APIs
APIs for managing sources and Views are available in the Developer Portal.
Refer to Source APIs and View APIs for more information.