The Platform offers unique support for database adaptive access using the policy resolution endpoint. This endpoint is designed to add/modify the SQL query the user is trying to perform, so that only authorized data is processed.
The BigQuery interceptor leverages the policy resolution endpoint to modify the Google BigQuery data selection, within the API calls, based on the decision from the policies.
Consistently protecting the same data assets across different databases is a challenge that many data owners struggle with. Often there is a lack of transparency around the authorizations that are enabled due to the different layers of permissions that can surround a database.
The Platform for managing access to data will provide the following main benefits:
- Unified Access Management - Manage access to data objects using a unified interface, that can provide consistent access decisions.
- Fine-grained access solution - Use an access solution that supports fine-grained access controls, both on row and column level.
- Central enforcement layer - Implement a central enforcement layer for all data access.
Architecture Flow
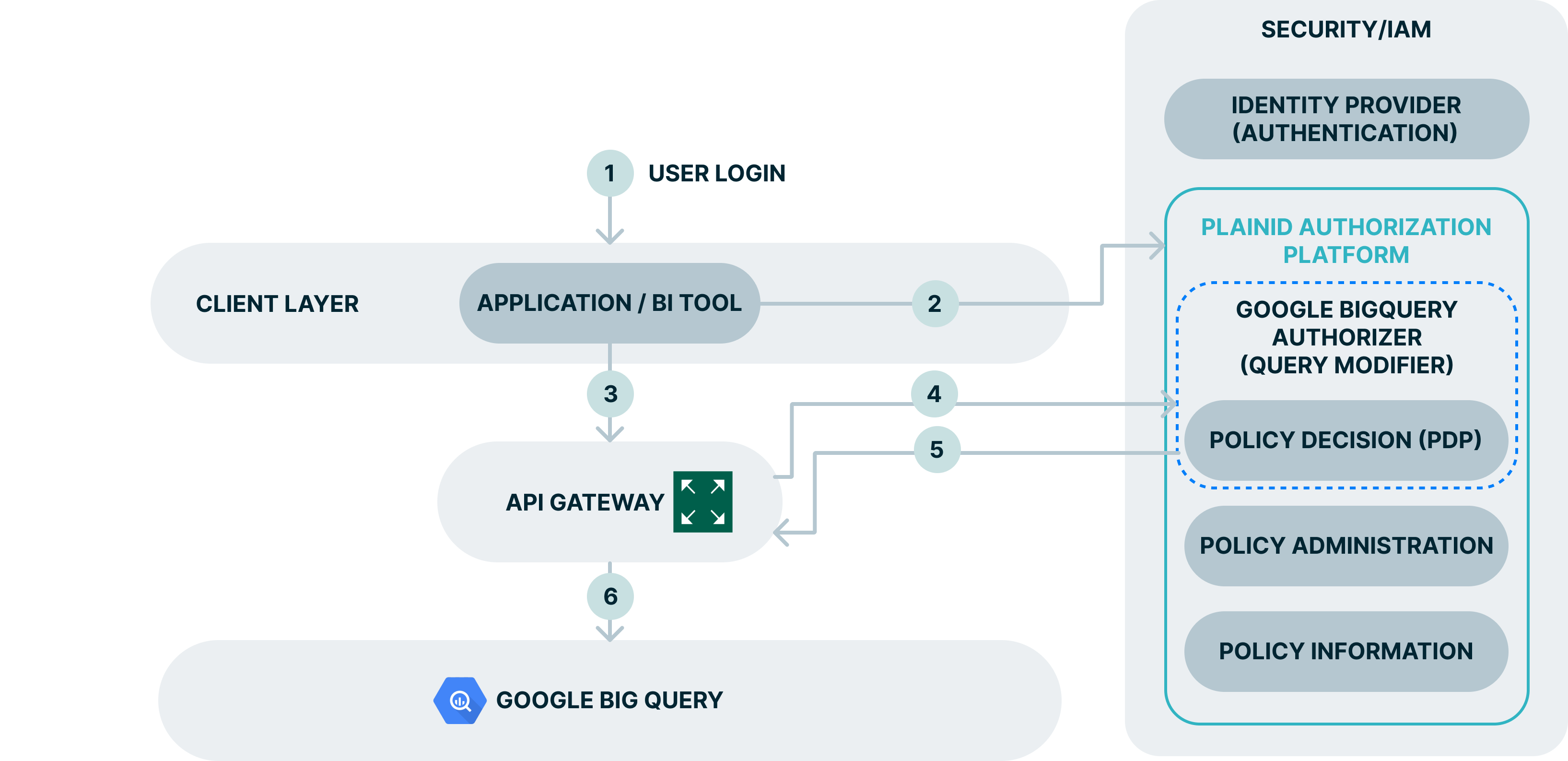
Explanation:
- Authenticated users access the application/service
- Applications and services use data APIs to access the data.
- The request is directed through an API Gateway, where it’s intercepted and sends to Data interceptor service”.
- The data interceptor service requests a “policy resolution” decision from the Platform PDP at the time of access.
- The response is translated to a data filtering cluse and a list of authorized data elements, this is used to modify the original data query.
- The data API request continues to the relevant repositories with the modified query. Required data, with the filtering based on the access controls, is send back to the application.
Prerequisites
In order to configure the PlainID Google BigQuery Authorizer, you need to create a Service Account in Google Cloud Platform:
- Create a GCP Service Account in the GCP IAM
- Grant the following Roles to the created Service Account:
- BigQuery Connection User
- BigQuery Data Viewer
- BigQuery User
- Create a new Key for the Service Account
- Download the Key in JSON format and save it into a file, e.g.
creds.json
Implementing effective access control for Google BigQuery requires precise configuration of Asset Types. A General Access Policy defines how resources are protected based on Attributes such as projects, datasets, tables, and columns. This document outlines the steps to configure Asset Types for row-level and column-level access control and install the BigQuery Interceptor to enforce these policies.
By following these instructions, you can establish a robust access control framework for your BigQuery assets, ensuring security and compliance with organizational policies.
How it Works
The Authorizer enforcement flow integrates dynamic Policy evaluation to modify SQL queries before execution. This streamlined process provides granular control over row-level and column-level access, safeguarding sensitive data while aligning with the organization's data governance framework. The process operates as follows:
- User Access and Authentication: A user accesses the application, which redirects them to authenticate via the Identity Provider (IdP).
- Query Submission: The application sends an SQL request to the PlainID Google BigQuery Authorizer. This component functions as a Query Modifier and evaluates the request using dynamic Policy modeling.
- Policy Evaluation and Query Modification: The Authorizer enforces access control by applying the defined Policies. It modifies the original query based on the user's permissions and returns the updated query to the application.
- Query Execution: The Application submits the modified query to Google BigQuery for execution, ensuring compliance with organizational access control policies.
Flow Diagram
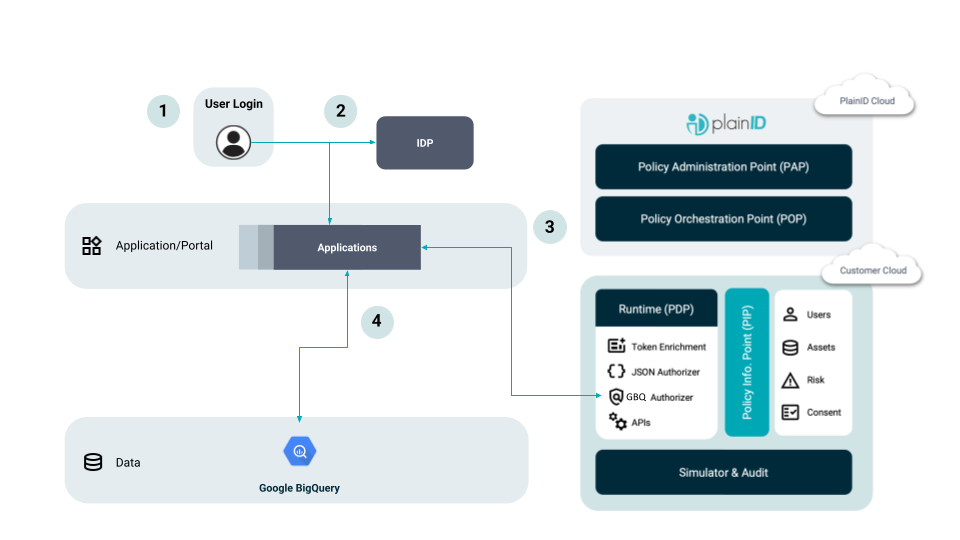
- The user accesses the app.
- The user is redirected to complete the authentication process on the Identity Provider (IdP).
- The application sends the SQL request to the PlainID Google BigQuery Authorizer. The Authorizer is a Query Modifier – a PDP component designated for Google BigQuery that modifies queries based on the dynamically calculated access decision. The modified query is sent back to the application.
- The modified request is sent to Google BigQuery by the Application (specific path based on each Application’s unique architecture).
Authorizer Request and Parameters
The POST /enforcer/bigquery/{projectId}.{datasetName} endpoint allows users to submit SQL queries for enforcement based on Policy Resolution rules. This API processes incoming queries and applies access control measures according to the defined Policies. Users can configure various parameters to customize the query execution, including options for debugging and formatting.
The request body must include the SQL query along with the necessary Runtime resolution credentials to ensure accurate Policy enforcement.
Endpoint
POST /enforcer/bigquery/{projectId}.{datasetName}?pretty=false&dry=false
Headers
| Header | Description | Required | Values |
|---|---|---|---|
Content-Type |
Must be application/json |
Yes | application/json |
Accept |
Default is application/json. Also supports text/plain. |
No | application/json, text/plain |
Parameters
| Parameter | Type | Required | Default | Values | Description |
|---|---|---|---|---|---|
projectId |
string | No | - | Any valid project ID | Project identifier |
datasetName |
string | No | - | Any valid dataset name | Dataset name |
pretty |
boolean | No | false |
true, false |
Enables formatting |
dry |
boolean | No | false |
true, false |
The "dry run" parameter avoids applying rules and returns incoming SQL without any changes (according to Policy Resolution rules) |
debug |
boolean | No | false |
true, false |
Adds debug info such as requestId, enforcerProperties, and cacheProperties. |
Body
| Field | Type | Description |
|---|---|---|
sql |
string | SQL query. |
resolution |
object | Runtime Resolution credentials. |
Policy Modeling
Asset Type Configuration for Google BigQuery
Row-Level Security (RLS) and Column-Level Security (CLS) are key access control mechanisms in Google BigQuery that help enforce data governance by restricting access based on user roles and attributes. For more information about Asset Type Configurations, refer to our documentation on Data Access Policies
Google BigQuery Special Modeling Instructions
Google BigQuery includes special modeling instructions that help enforce fine-grained access control and ensure data governance by aligning policies with BigQuery’s project, dataset, and table structure. These instructions provide guidelines for configuring RLS and CLS to manage access based on user roles and attributes.
Row-Level Security (RLS)
RLS controls access to specific rows within a BigQuery table based on predefined conditions. Policies are applied using Asset Types that align with BigQuery’s project, dataset, and table hierarchy. The naming convention must follow project_ID.dataset.table_name, ensuring consistency with BigQuery’s structure.
- Global Policies: Use an asterisk (
*) to define Policies that apply across multiple datasets or tables (e.g.,project_ID.*.*). - Asset Attributes: The Attribute names used in Policies must correspond exactly to the column names in BigQuery and are case-sensitive.
Example Use Case: A sales manager can only access rows related to their assigned region within the sales_data table, while another manager has access to a different region.
Column-Level Security (CLS)
CLS restricts access to specific columns within a table to control exposure of sensitive data. Policies are defined using mandatory Asset Attributes that map directly to BigQuery components, ensuring precise control over data visibility.
-
Mandatory Attributes:
Parameter Description columnBigQuery Column Name projectidBigQuery Project ID datasetBigQuery Dataset Name tableBigQuery Table Name -
Ensure these attributes align with BigQuery’s project, dataset, and table hierarchy.
Example Use Case: A policy can be applied to restrict access to thebalancecolumn in theaccounttable within theds1dataset underproject1, ensuring that only authorized users can view financial data.
By implementing RLS and CLS, organizations can enforce fine-grained access control, ensuring compliance with security policies while maintaining flexibility in data management.
Authorizer Setup and Configuration
Prerequisites
In order to configure the PlainID Google BigQuery Authorizer, you need to create a Service Account in Google Cloud Platform:
- Create a GCP Service Account in the GCP IAM
- Grant the following Roles to the created Service Account:
- BigQuery Connection User
- BigQuery Data Viewer
- BigQuery User
- Create a new Key for the Service Account
- Download the Key in JSON format and save it into a file, e.g.
creds.json
Installation
This section outlines the installation process for the BigQuery Interceptor, which integrates with the PlainID platform to enforce Policy-based access control.
To install the Platform BigQuery Interceptor:
- Pull the BigQuery Interceptor container image from the PlainID Container Registry using the
docker pullcommand:
For example:docker pull <platform registry location>:<version>docker pull gcr.io/plainid-presales/bigquery:1.0 - Create a secret from the credentials JSON:
Example:kubectl create secret generic google-creds --from-file=<json location>kubectl create secret generic google-creds --from-file=query-enforcer/creds.json - Update the
bigq.yamlfile as needed (see Sample Configuration below). - Apply the configuration:
kubectl apply -f bigq.yaml
Configuration
This section lists the key properties for customizing the BigQuery integration, including connection settings.
Sample Configuration bigq.yaml
This sample bigq.yaml contains the following configurations:
- Configmap
- Service
- Deployment
- Secret (Optional)
apiVersion: v1
# ConfigMap
data:
application.properties: |
server.port=8080
#server.tomcat.uri-encoding=UTF-8
#server.error.whitelabel.enabled=false
logging.config=classpath:logback-spring.xml
# The PlainID logging level options include trace, debug, info, error, and OFF.
logging.level.org.springframework=OFF
logging.level.org.springframework.core=OFF
logging.level.org.springframework.beans=OFF
logging.level.org.springframework.context=OFF
logging.level.org.springframework.transaction=OFF
logging.level.org.springframework.web=OFF
logging.level.org.springframework.test=OFF
logging.level.org.springframework.data=OFF
logging.level.com.google.zetasql=info
logging.level.com.plainid=error
spring.main.banner-mode=OFF
spring.http.encoding.charset=UTF-8
spring.http.encoding.enabled=true
spring.http.encoding.force=true
spring.mvc.throw-exception-if-no-handler-found=true
spring.resources.add-mappings=false
spring.redis.host=redis.example.com
spring.redis.port=6379
spring.redis.password=SXSIvHJo1OzaWnU2YHZ8p3us0z
spring.data.redis.ssl.enabled=true
management.security.enabled=false
management.endpoints.enabled-by-default=false
management.endpoints.web.exposure.include=info, health
management.endpoint.info.enabled=true
management.endpoint.health.enabled=true
management.endpoint.health.show-components=always
management.endpoint.health.show-details=always
management.endpoint.health.probes.enabled=true
management.endpoint.health.group.liveness.include=livenessState
management.endpoint.health.group.liveness.show-details=always
management.endpoint.health.group.readiness.include=readinessState
management.endpoint.health.group.readiness.show-details=always
management.health.postgres.enabled=true
management.health.readinessstate.enabled=true
management.info.git.mode=full
spring.cloud.gcp.core.enabled=false
spring.cloud.gcp.bigquery.enabled=false
app.request-context.prefix=context
# update the following parameter to your PDP URL
app.policy-resolution.api-url=https://URL-TO-PDP-RUNTIME/api/runtime/resolution/v3
app.cache.prefix=query-enforcer.v2
app.cache.ttl-policy-resolution=3000
app.cache.ttl-db-schema-initial-delay=3000
app.cache.ttl-db-schema=600000
app.cache.ttl-catalog=300000
# update to the full path of the GCP Service Account Credentials file:
app.enforcer.bigquery-credential-files[0]=file:creds.json
app.enforcer.resolutionresponse-empty=deny
app.enforcer.resolutionaccess-empty=deny
app.enforcer.resolutionprivileges-empty=allow
app.enforcer.ignoreforbidden-columns=deny
app.enforcer.columnenforcermasks[string]=***
app.enforcer.resolutionmasking-as-column=deny
app.enforcer.resolution-attribute-projectId=projectid
app.enforcer.resolution-attribute-dataset=dataset
app.enforcer.resolution-attribute-table=table
app.enforcer.resolution-attribute-column=column
app.enforcer.bigquery-information-schema=allow
app.enforcer.ignore-enforcer-fails=deny
# app.enforcer.ignore-tables[0]=plainid-142815.*.*
app.enforcer.ignore-forbidden-columns=deny
# SSL configuration (Uncomment to enable SSL)
# The format used for the keystore. It could be set to JKS in case it is a JKS file
# server.ssl.key-store-type=PKCS12
# The path to the keystore containing the certificate
# server.ssl.key-store=/app/keystore.jks
# The password used to generate the certificate
# server.ssl.key-store-password=111
# The alias mapped to the certificate
# server.ssl.key-alias=111
# security.require-ssl=false
kind: ConfigMap
metadata:
name: bigq-config
---
# Service
apiVersion: v1
kind: Service
metadata:
name: bigq
spec:
selector:
app: bigq
ports:
- name: "bigq"
protocol: "TCP"
port: 8080
targetPort: 8080
---
#Deployment and Optional Secret
apiVersion: apps/v1
kind: Deployment
metadata:
name: bigq
spec:
selector:
matchLabels:
app: bigq
strategy:
rollingUpdate:
maxSurge: 2
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
labels:
app: bigq
spec:
containers:
# The following 3 lines are optional - depending on the used redis - internal or managed
- image: redis
name: redis
resources: {}
# Use the Image and Tag provided by PlainID
- image: plainid/authz-bigquery:5.2321.0
imagePullPolicy: Always
name: bigq
resources: {}
volumeMounts:
- name: bigq
mountPath: /app/application.properties
subPath: application.properties
- name: creds
mountPath: /app/creds.json
# The name of the credentials JSON file - matching the name of the local file `creds.json`
subPath: creds.json
volumes:
- name: bigq
configMap:
name: bigq-config
- name: creds
secret:
secretName: google-creds
Configuration Properties
| Property | Description | Values |
|---|---|---|
app.policy-resolution.api-url |
The Runtime Resolution API URL | Example: https://localhost:8010/api/runtime/resolution/v3 |
app.policy-resolution.connection-timeout |
Sets the connection timeout in milliseconds | Default: 10000 |
app.policy-resolution.socket-timeout |
Sets the socket timeout in milliseconds | Default: 60000 |
app.policy-resolution.automatic-retries |
Toggle disabling automatic retries (up to 4 times) for socket timeouts | Default: true |
app.bigquery.total-timeout |
totalTimeout has ultimate control over how long the logic should keep trying the remote call until it gives up completely. The higher the total timeout, the more retries can be attempted. | Default: 0 milliseconds |
app.bigquery.initial-retry-delay |
InitialRetryDelay controls the delay before the first retry. Subsequent retries use this value adjusted according to the RetryDelayMultiplier. | Default: 0 milliseconds |
app.bigquery.max-retry-delay |
MaxRetryDelay puts a limit on the value of the retry delay, so that the RetryDelayMultiplier cannot increase the retry delay higher than this amount. | Default: 0 milliseconds |
app.bigquery.retry-delay-multiplier |
RetryDelayMultiplier controls the change in retry delay. The retry delay of the previous call is multiplied by the RetryDelayMultiplier to calculate the retry delay for the next call. | Default: 1.0 |
app.bigquery.max-attempts |
MaxAttempts defines the maximum number of attempts to perform. If this value is greater than 0, and the number of attempts reaches this limit, the logic will give up retrying, even if the total retry time is still lower than TotalTimeout. | Default: 0 |
app.cache.prefix |
Redis cache prefix | Default: query-enforcer.v2 |
app.cache.ttl-policy-resolution |
Cache TTL in milliseconds for Policy Resolution response | Default: 300000 (5m) Minimum: 2000 (2s) |
app.cache.ttl-db-schema |
Cache TTL in milliseconds for BigQuery request | Default: 10800000 (3h) Minimum: 60000 (1m) |
app.cache.ttl-catalog |
Cache TTL in milliseconds for building internal DB schema for dataset from enforcer request | Default: 600000 (10m) Minimum: 10000 (10s) |
app.enforcer.bigquery-credential-files |
List of GCP credential filenames if empty or not defined the workload identity will be used for authentication. The first credentials file is used as default in cases where the project user is querying doesn't have a designated file. |
Example: app.enforcer.bigquery-credential-files[0]=project-12345.json |
app.enforcer.resolution-response-empty |
How to act in case there is no response (empty response) from the Policy Decision Point. allow – enable access without any limitations. deny – block all access. |
Default: deny |
app.enforcer.resolution-access-empty |
How to act in case response includes row level policy only (no column level response). allow – All columns are returned to the user. deny – All columns are masked. |
Default: deny |
app.enforcer.resolution-privileges-empty |
How to act in case the response includes column level policy only, (No row level response). allow – no limitation on row level. deny – no rows are returned to the user |
Default: deny |
app.enforcer.resolution-masking-as-column |
How to act in case the response from Policy Decision Point does not contain any access but does contain masking instruction.allow – mask all columns in the table based on masking instructions.deny – block all access.Note: this is relevant only when app.enforcer.resolution-response-empty is defined as denyV2.4 and above |
Default: deny |
app.enforcer.resolution-attribute-projectId |
Name of "projectId" attribute in policy Asset Template | Default: projectid |
app.enforcer.resolution-attribute-dataset |
Name of "dataset" attribute in policy Asset Template | Default: dataset |
app.enforcer.resolution-attribute-table |
Name of "table" attribute in policy Asset Template | Default: table |
app.enforcer.resolution-attribute-column |
Name of "column" attribute in policy Asset Template | Default: column |
app.enforcer.resolution-masking-resource-type-name |
Name of the Asset Template used to manage masking instructions. V2.4 and above |
Default: Masking_Instructions |
app.enforcer.resolution-attribute-maskAs |
Name of attribute used to manage the masking instruction within the Asset Template V2.4 and above |
Default: maskas |
app.enforcer.bigquery-information-schema |
Supporting queries with using information_schema tables. Possible values: allow or deny. After changing this value the DB schema cache must be updated. |
Default: allow |
app.enforcer.ignore-enforcer-fails |
Indicates what to do in case a SQL query that can’t be parsed is sent to the enforcer. Possible values: allow or deny |
Default: deny |
app.enforcer.ignore-tables |
List of tables with full name “project.dataset.table” to ignore for enforcing. It is possible to use “*” (star) instead of name for each part. | Example: app.enforcer.ignore-tables[0]=*.*.members |
app.enforcer.ignore-forbidden-columns |
A behavior of using a forbidden column is sent within the WHERE clause of SQL query. Possible values: allow or deny |
Default: deny |
app.enforcer.bigquery-prefetch-db-schema |
Filtering used metadata based on mentioned tables in SQL. If true might be received RESOURCE_EXHAUSTED error in case BigQuery contains a very big list of datasets/tables/columns.If false the metadata will be fetched at runtime.V2.2 and above |
Default: true |
app.enforcer.column-enforcer-masks[coulmnType] |
Define default masking instruction per Column Type. Will be considered in case no masking instruction will return from the Policy Decision Point V2.4 and above | Examples:app.enforcer.column-enforcer-masks[string]=***app.enforcer.column-enforcer-masks[numerical]=-1app.enforcer.column-enforcer-masks[bool]=falseapp.enforcer.column-enforcer-masks[timestamp]=0app.enforcer.column-enforcer-masks[date]=2007-12-03app.enforcer.column-enforcer-masks[time]=10:15:30 |
Authentication to PDP in Google BigQuery (GBQ) Integration
This section details the methods for authenticating with the Policy Decision Point (PDP), including configuration options for scopes using client secrets or JWTs, as well as advanced use cases for passing additional headers.
Authentication to the PDP is managed at the Scope level. Follow these guidelines based on your Scope configuration:
Scopes Using Client Secrets
- For Scopes configured to work with a Secret, the client calls the GBQ Authorizer using a Client Secret.
Scopes Using JWTs
- For Scopes configured with JWTs, the client sends the JWT as the
Authorizationheader when calling the GBQ Authorizer. - Additionally, configure the GBQ Authorizer to allow the
Authorizationheader to pass through by addingAuthorizationto theHEADERS_PASS_THROUGH_WHITE_LISTsetting.
Including Additional Headers
- If your application requires passing additional headers to the PDP, include them in the
HEADERS_PASS_THROUGH_WHITE_LISTsetting, regardless of the Scope's authentication method. - For example, to pass an external request ID such as
X-Request-ID, include it in the headers pass-through configuration. This setup supports advanced use cases such as injecting custom headers.